Start a Crunch pilot
Experience savings potential of Crunch using a sample of your data
The easiest way to get prove out the value of Crunch compression optimization in your environment is to initiate a pilot. A Crunch pilot is quick and easy, typically lasting 2-3 weeks start to finish.
Success criteria - what a pilot will achieve
- Quantify the storage reduction capabilities of Granica Crunch on your representative Parquet dataset
- Validate that data integrity is maintained throughout the compression lifecycle
- Validate that end-to-end data pipeline and query performance remains unaffected post-compression
By demonstrating the effectiveness of Granica Crunch across a representative sample of your data and your queries, a pilot aims to build confidence in the ability of Crunch to deliver value across your entire data lakehouse. Pending successful pilot results, the remainder of your datasets will be prioritized for compression during the production rollout phase based on size, usage patterns, and business criticality.
Deployment options
As part of the Granica Crunch pilot you have the flexibility to choose between two deployment architectures depending on your preferences and security considerations: a SaaS Deployment or a Hosted Deployment. Both deployment options provide seamless integration with your existing cloud infrastructure. The SaaS Deployment is best suited for minimizing costs and operational complexity securely, while the Hosted Deployment is best for those prioritizing security and control.
SaaS Deployment
The SaaS Deployment is a fully managed service, reducing operational overhead by allowing Granica to handle infrastructure and data processing in its secure cloud environment. Data is processed with encryption (in transit and at rest), and compliance requirements are met with collaboration from your security team.
- Data Handling: Data resides in your cloud environment, and Granica accesses it via IAM read permissions. Data is securely transferred to the Granica Cloud, where the original dataset (Control) and compressed dataset (Crunched) are processed and available for side-by-side comparison.
- Key Benefits: Simplifies operations, reduces infrastructure costs, and ensures seamless integration with your analytics stack, preserving data integrity and performance.
- Prerequisites: Complete necessary legal/security approvals and provide read-only IAM permissions.
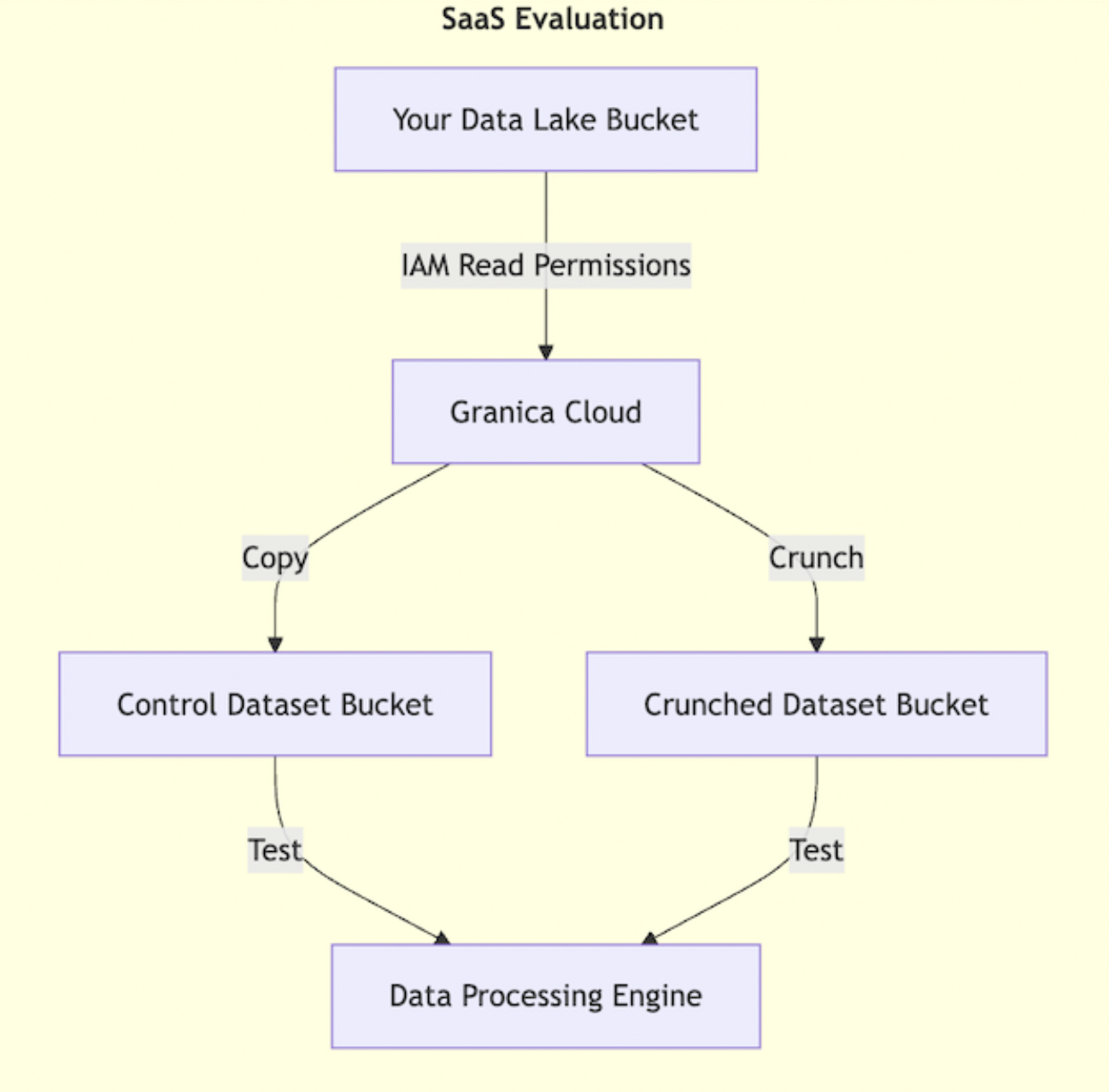
- Your Data Lake Bucket: The data resides in your cloud environment. Granica is granted IAM read permissions to access the data lake.
- Granica Cloud: Data is transferred securely to the Granica Cloud environment within the same region of the Customers data. Two actions are performed:
- Control Copy: The original dataset is copied into a Control Dataset Bucket.
- Crunch Process: Data is processed and compressed by Granica's Crunch engine and stored in a separate Crunched Dataset Bucket.
- Data Processing Engine: The control and crunched datasets undergo a series of processes to ensure data integrity, performance, and compatibility. These checks validate schema preservation, query performance, data consistency, and execution speed. They ensure that the compressed data retains its original structure and integrates seamlessly into your analytics stack, maintaining functionality and performance without loss of integrity.
Hosted Deployment
The Hosted Deployment offers more control, operating within your cloud sub-account. Granica's Crunch engine processes data in a sandboxed environment, providing greater visibility and adherence to your security policies.
- Data Handling: Data remains in your cloud, with a control dataset copied to your environment. Granica processes the data in your sandbox and securely stores the crunched dataset.
- Key Benefits: Enhanced security, cost flexibility, and full control over resource allocation. Ideal for organizations with strict compliance and security requirements. Refer to section 4.1 for applicable security measures.
- Prerequisites: Provision a dedicated sub-account, configure VPC endpoints for secure communication, and ensure appropriate security and network configurations.
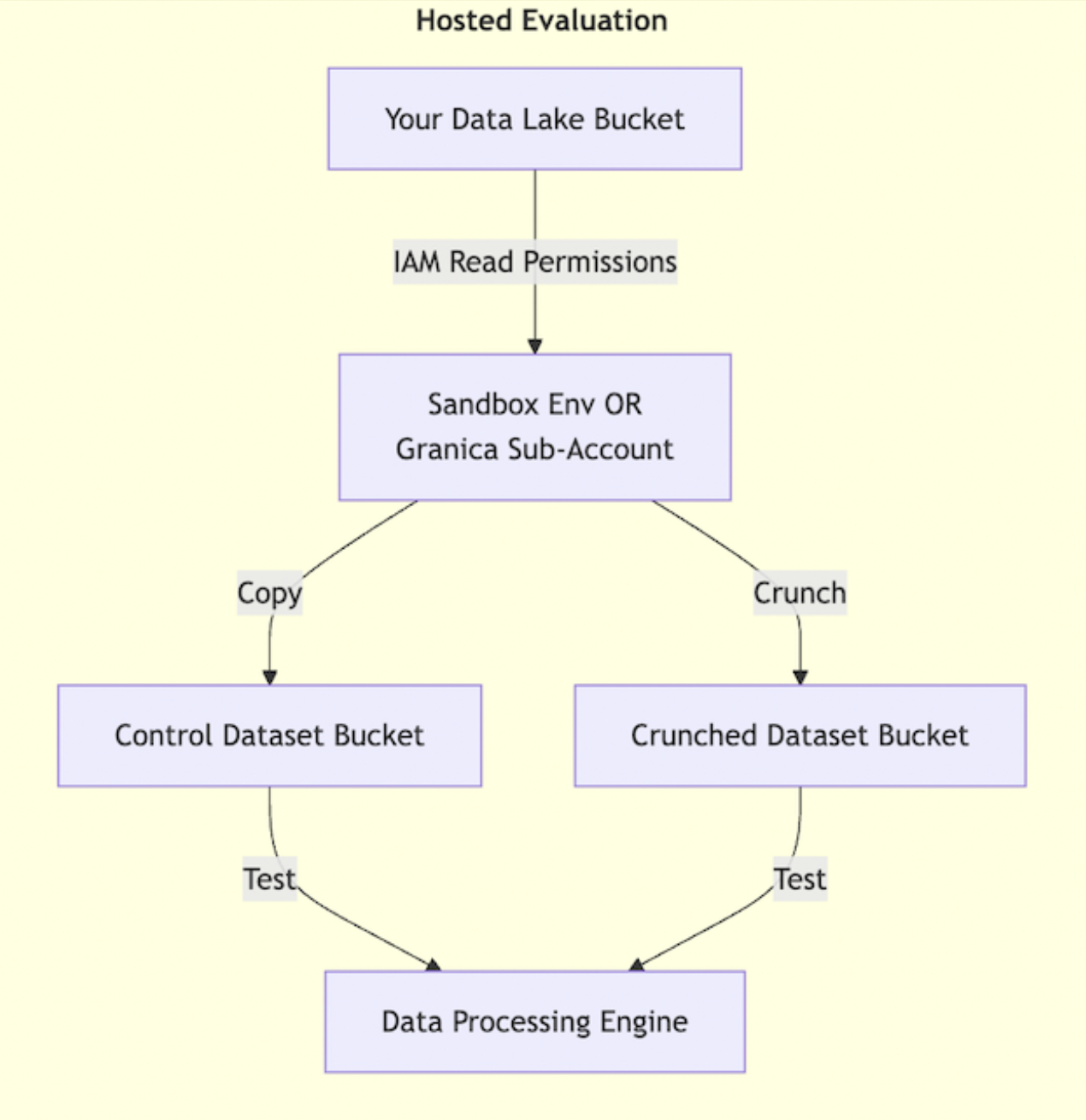
- Your Data Lake Bucket: Your data remains in your cloud, with IAM read permissions granted to Granica.
- Granica Sub-Account (Sandbox Environment): Data is processed in a Granica-managed sandbox within your own sub-account.
- Control Copy: A copy of the original dataset is placed in a Control Dataset Bucket in your environment.
- Crunch Process: Data is compressed by Granica's Crunch engine and stored in a Crunched Dataset Bucket within your sub-account.
- Data Processing Engine: The control and crunched datasets undergo a series of processes to ensure data integrity, performance, and compatibility. These checks validate schema preservation, query performance, data consistency, and execution speed. They ensure that the compressed data retains its original structure and integrates seamlessly into your analytics stack, maintaining functionality and performance without loss of integrity.
Get started
Our pilot process is simple yet comprehensive. You can see a sample pilot report to help you understand the end-to-end process.
Contact our product team to initiate a pilot today. The process is fast and easy and you'll soon be well on your way to reducing costs and speeding queries in your lakehouse.