How crunching works
Understand how Crunch crunches your data.
Once you've deployed Granica into your cloud environment, it's time to get crunching. Crunching" is our fun euphemism for "data processing" in the context of compression optimization, where we "crunch" the data down to it's purest information-rich state.
The Granica Crunch lakehouse compression optimizer works first and foremost at the bucket level. You first specify buckets which are eligible to be crunched via policy, and then you run the granica crunch <bucket_name> to begin crunching an eligible bucket and the columnar files within it.
Production lakehouse data
Production lakehouse data is the columnar data your teams are generating and working with every day. This section illustrates the two different mechanisms Crunch offers to compress and optimize that data. Runtime Crunch optimizes net-new files in real-time as they are written, while background Crunch optimizes already written columnar files. The following table compares/contrasts the two modes:
| Runtime Crunch | Background Crunch | |
|---|---|---|
| Optimizes compression of incoming data (as it is written) | Yes | No |
| Optimizes compression of existing data | No | Yes |
| Continuously learns from your data to improve compression optimization | Yes | No |
| Compatibility | Any application or system using the open source Parquet writer | Specific qualified platforms |
| Availability | Via early access | Now |
Some (perhaps all) of your production lakehouse data may also require regular backup copies transferred to a remote region for disaster recovery purposes. Crunch can help here too - see the next section on disaster recovery.
Crunch lexicon
- Crunched buckets are those which have been put under active management, processing and monitoring by Crunch. A bucket is in the state "crunched" immediately after you run the
granica crunchcommand. - Crunched objects are those objects in a crunched bucket which have been evaluated by Crunch for (a) compression optimization potential (background mode only) or (b) to develop compression optimization recipes (runtime mode only)
- Vanilla buckets are those which have not been crunched.
- Vanilla objects are those which have not been crunched. All objects in a vanilla bucket are by definition vanilla objects. Objects in a crunched bucket that are yet to be processed (i.e. crunched!) are also vanilla objects.
- Ingested objects are those which have been crunched and reduced (background mode only).
- Analyzed objects are those which have been crunched and analyzed to generate optimal compression optimization recipes (runtime mode only).
Runtime crunch write workflow
In this mode Crunch has two main components. The first is an ML-powered adaptive compression control system which analyzes your existing columnar files to create compression optimization recipes. The control system continuously learns from and adapts to your data over time, ensuring that Crunch compression optimization strategies evolve with your data. The control system operates in the background without impacting your data pipelines or requiring manual intervention.
The second is a runtime optimizer SDK which integrates into your data platform and is invoked transparently by any applications or systems utilizing an open source apache Parquet writer, without any code changes. This SDK utilizes the compression optimization recipes generated by the control system to optimize columnar files in real-time as they are written, with minimal configuration and operational overhead. In this way your columnar files are optimized the instant they are created, maximizing savings and performance across your lakehouse.
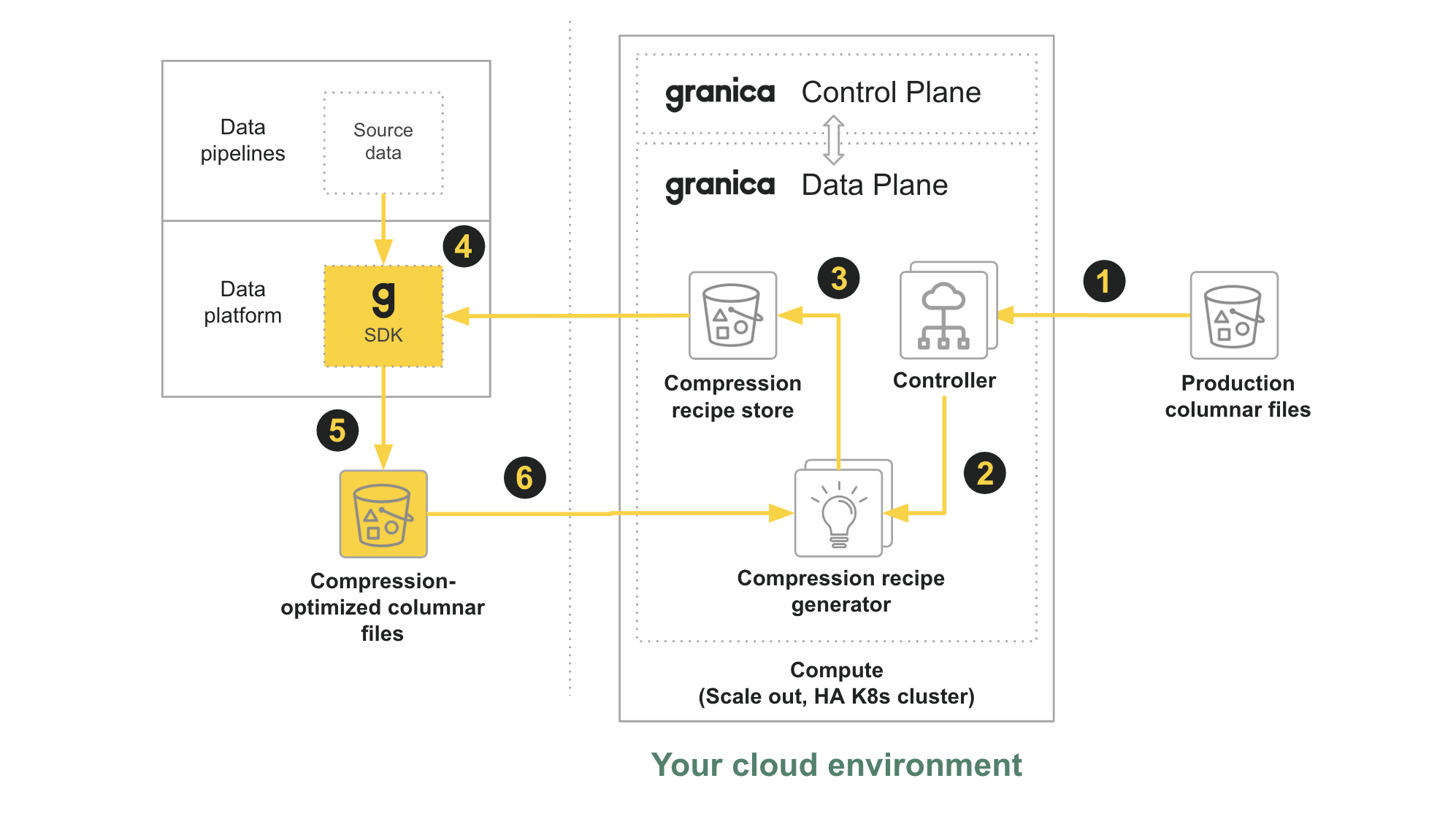
1. User runs the granica crunch CLI command to initiate crunching on an eligible vanilla source data bucket containing columnar files, in our case the Production columnar files bucket, at which time the bucket becomes a Crunched bucket as it is now managed and monitored by Crunch. The Controller component of Crunch retrieves a copy of any vanilla objects (files) in the Crunched bucket using LIST and GET operations.
2. The Controller routes the vanilla objects to a Compression recipe generator, which analyzes the unique characteristics and structure of the columnar files to create, or update, compression optimization recipes. From the point of view of the Crunched bucket, the objects have been analyzed by Crunch.
3. The Compression recipe generator updates the Granica Compression recipe store bucket with new or updated recipes.
4. Spark-based applications initiate columnar writes using standard commands such as:
The Granica runtime Crunch SDK, configured inside the Spark infrastructure, intercepts the write operation. It checks the Compression recipe store for the best available compression optimization recipe for the data, and applies that recipe or defaults to standard compression settings if no recipe is available.
5. The Granica runtime Crunch SDK writes the data out in standard, lakehouse-native format (typically Parquet) where it can be read by any standards-based application.
6. The runtime SDK notifies the compression optimization system, particularly the Compression recipe generator, to analyze the newly created file to update existing recipes or create a new one. In this way runtime Crunch employs a continuous feedback and learning loop to adapt and optimize over time.
note
Crunch is not in the read path and reading Granica Crunch compressed files is transparent, i.e. once written, any application or system utilizing the open source Parquet reader can immediately read them normally. For example in a Spark environment, simply use standard read commands such as:
Because the physical files are now smaller than they would have been without Crunch, you may even see your query speeds and data loading speeds increase, dependent on your query patterns.
tip
Runtime Crunch optimization is available to select design partner customers - request Early Access.
Background crunch write workflow
In this mode Crunch monitors your buckets for incoming columnar files from your spark-based applications, and crunches those files in the background. Once your data is crunched you’ll see immediate savings in your lakehouse storage costs.
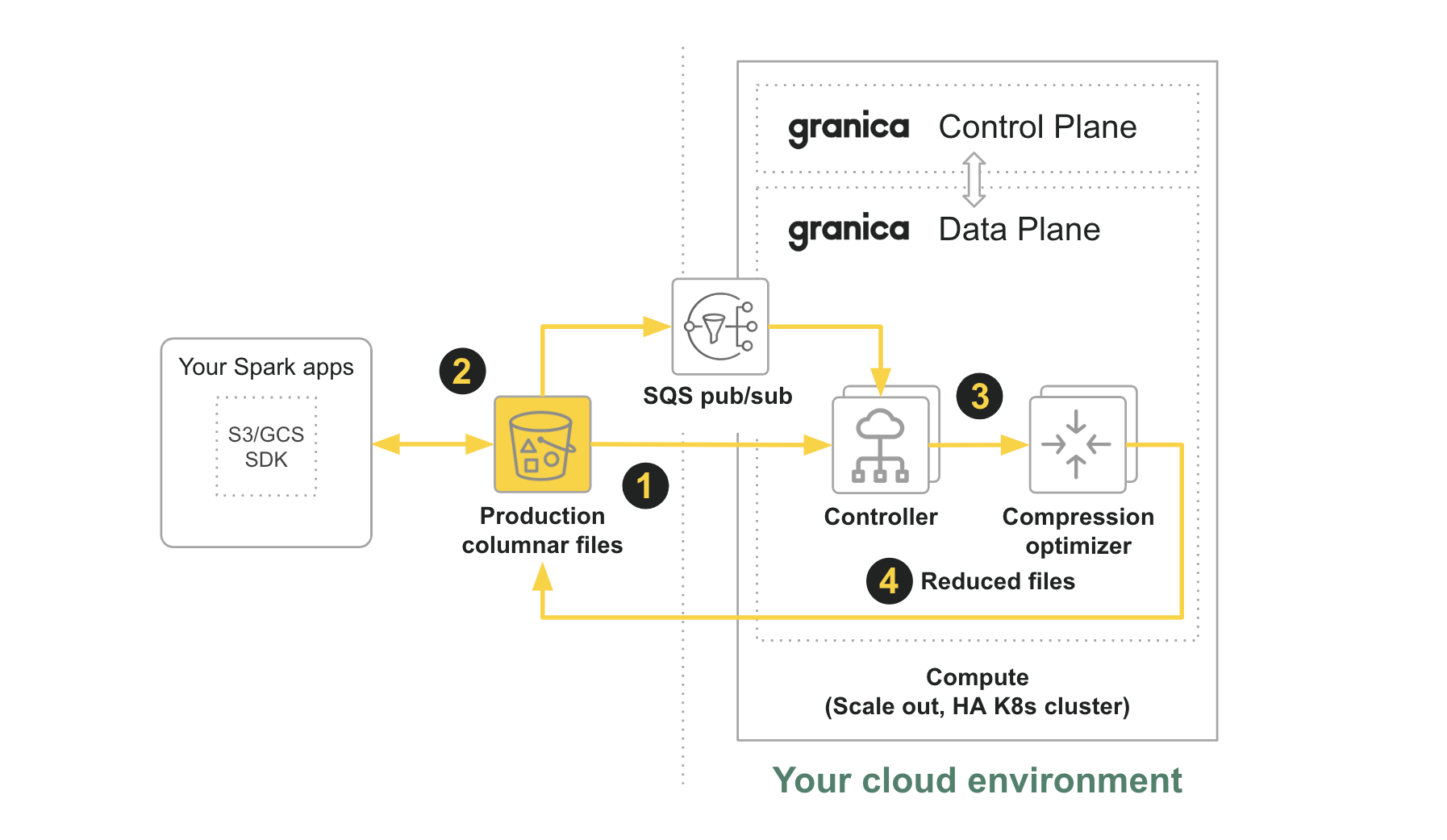
1. User runs the granica crunch CLI command to initiate crunching on an eligible vanilla source bucket, in our case the Production columnar files bucket, at which time the bucket becomes a Crunched bucket as it is now managed and monitored by Crunch. The Controller component of Crunch retrieves a copy of any vanilla objects in the Crunched bucket using LIST and GET operations.
2. When an application or user issues write (PUT) requests to the Crunched bucket, the Controller receives notifications about the new vanilla objects via real-time SQS pub/sub events and GETs the objects from the Crunched bucket.
3. The Controller sends the vanilla objects to a load balanced Compression optimizer component.
4. The Compression optimizer validates with Crunch policy whether the vanilla objects are eligible to be crunched. If they are not eligible, the objects are not processed. If they are eligible, the Compression optimizer optimizes the compression and encoding of the file to reduce its physical size and swaps the original vanilla object with the newly optimized object, thus intiating a reduction in your monthly cloud storage bill. The degree of size (and cost) reduction varies based on the pre-existing structure and compression of the vanilla object. From the point of view of the Crunched bucket, the objects have been ingested by Crunch.
note
As with runtime mode, Crunch is not in the read path and reading Granica Crunch-optimized files is transparent. Crunch swaps the original files with smaller, compression-optimized versions. The underlying mechanism of the swap operation is customizable and our product experts can advise you based on your specific environment. Applications and systems which support the swap and which also utilize the open source Parquet reader will then begin reading the newly reduced (i.e. ingested) files normally. For example in a supported Spark environment, simply use standard read commands such as:
Because the physical files are now smaller you may even see your query speeds and data loading speeds increase, dependent on your query patterns.
note
When you crunch a bucket currently in the Amazon S3 IT storage class, the crunched data will change to the frequently accessed sub-class of S3 IT (i.e. the most expensive sub-class) regardless which sub-class it was previously in, thus resetting the S3 IT "clock". Depending on access patterns this reset may/may not incur incremental operational costs.