Crunch pilot sample report
Understand the end-to-end pilot process.
This document provides a sample pilot report to help you understand what to expect out of a Granica Crunch pilot and evaluation. Throughout it uses "[Customer Name]" to reflect the specific customer involved. Let's dive in.
Executive Summary
This document outlines the pilot project to evaluate Granica's lakehouse compression optimization solution for improving the cost efficiency and performance of [Customer Name]'s data platform.
| No. | Description | Status |
|---|---|---|
| 1 | Reduce storage footprint by ≥50% on pilot dataset | Not Started |
| 2 | Maintain 100% data integrity and fidelity | Not Started |
| 3 | Ensure no degradation in query performance vs. baseline | Not Started |
| 4 | Demonstrate compatibility with existing data lakehouse | Not Started |
| 5 | Expedite procurement process | Not Started |
The pilot ran from STARTDATE to ENDDATE on XX TB of data representative of [Customer Name]'s overall parquet data lakehouse, including high-cardinality time-series data, sparse datasets, and dense complex nested schemas.
Granica Crunch was deployed in a dedicated AWS/GCP account/project with secure read access to [Customer Name]'s S3/GCS data lakehouse. The solution was rigorously tested for data reduction, data integrity and performance prior to production deployment.
Success of the Granica Crunch pilot at [Customer Name] marks a significant milestone in [Customer Name]’s data journey, showcasing the substantial benefits of Granica’s intelligent compression in reducing storage costs, enhancing query performance, and enabling new analytics and AI use cases.
Key Achievements:
- XX% storage reduction across pilot datasets, with up to XX% on the largest dataset.
- 100% data integrity and schema compatibility, confirmed through rigorous testing.
- Over XX% projected compute efficiency improvement for queries on crunched datasets.
- No performance penalty on end-to-end queries.
- Seamless integration with existing data lakehouse query engines
These results give us high confidence in the ability of Granica Crunch to deliver significant value as projected below:
Ramping up in Year 1:
- Total Expected Savings: $X.XM
- Average ROI: XXX%
Thereafter Annually:
- Total Expected Savings: $X.XM - $Y.YM
- Average ROI: XXX%
- Note: This does not include data growth. ROI will naturally be higher with it.
Note: Total savings include reduced storage costs and projected compute and network savings from more efficient queries and data transfers.
Beyond immediate cost benefits, Granica Crunch positions [Customer Name] for long-term success by establishing a scalable, high-performance, and cost-efficient data architecture. Its seamless integration with existing tools and skill sets ensures rapid adoption and accelerates time-to-value.
Pilot Objectives and Success Criteria
The primary objectives of the Granica Crunch pilot at [Customer Name] are to:
- Validate the storage reduction capabilities of Granica Crunch on [Customer Name]'s dataset
- Target: Achieve ≥XX% reduction in storage footprint for pilot datasets
- Measured by: Comparing compressed data size vs original size
- Ensure data integrity is maintained throughout the compression lifecycle
- Target: 100% data integrity and fidelity preserved
- Measured by: Performing record counts, checksums, statistical sampling, and schema validation on compressed data
- Verify that end to end data pipeline performance remains unaffected post-compression
- Target: No degradation in overall end-to-end pipeline execution time
- Measured by: Granica internal Benchmarking Pipeline tests on original vs compressed data.
The pilot will be considered successful if all of the above criteria are met or exceeded.
Partial success will be determined if a subset of objectives are achieved. In the event that any of the objectives are not met, a joint [Customer Name]-Granica team will conduct a thorough root cause analysis and determine the necessary remediation steps prior to production rollout.
Pilot Scope and Datasets
The scope of the Granica Crunch pilot at [Customer Name] covers the compression and performance testing of ±XX TB of source data, representing ~Y% of [Customer Name]'s total XX PB parquet data lakehouse. The pilot datasets have been carefully selected to reflect the diversity of data characteristics observed across the entire data lakehouse.
Below are the specific datasets of the pilot, along with their sizes and characteristics:
| Dataset | Size (TB) | Characteristics |
|---|---|---|
| tbd | xx.xx | e.g. High cardinality, user activity log |
By demonstrating the effectiveness of Granica Crunch across this representative sample of datasets, the pilot aims to build confidence in the solution's ability to deliver value across [Customer Name]'s entire data lakehouse. Pending successful pilot results, the remainder of the datasets will be prioritized for compression in the production rollout phase based on size, usage patterns, and business criticality.
Out of scope for this pilot are:
- Compression of non-Parquet formats (e.g. ORC, CSV, JSON, Avro)
- Compression of datasets not explicitly listed above
- Integration with data catalog and data governance tools
- Evaluation of alternative compression technologies
- Performance testing on non-production clusters
- End-user training and documentation
Security Measures
The following security and access controls are implemented to ensure the protection of data throughout the pilot:
- Data Encryption: All data will be encrypted at rest using cloud provider’s server-side encryption, leveraging KMS (Key Management Service) for key management. Data in transit will be encrypted using TLS 1.2+ to ensure secure communication between components.
- Access Control: Granica will enforce least-privilege access by utilizing IAM roles and policies to restrict access to the minimum necessary resources, ensuring a secure operating environment.
- Monitoring and Logging: All access and activity within the pilot environment will be logged and monitored for auditing purposes, providing transparency and security oversight throughout the engagement.
- Collaboration with Security Teams: Granica will work closely with the customer’s security and compliance teams to verify that the pilot architecture meets all relevant security and regulatory requirements, ensuring full alignment with internal policies.
Deployment Approach
As part of the Granica Crunch pilot, customers have the flexibility to choose between two deployment architectures, depending on their preferences and security considerations: a SaaS Deployment or a Hosted Deployment. For this pilot, [Customer Name] has elected to use a XX architecture.
Pilot Execution Plan
The Granica Crunch pilot at [Customer Name] will be executed in four phases over the course of X weeks.
Phase 1: Plan and Prepare
| Deliverable | Owner | Date | Status |
|---|---|---|---|
| Signed pilot charter and statement of work | Both | mm/dd/yyyy | Not Started |
| SaaS/Hosted Deployment provisioned and configured | [Customer Name] | mm/dd/yyyy | Not Started |
| Access to [Customer Name] source datasets granted | [Customer Name] | mm/dd/yyyy | Not Started |
| Communication plan and meeting schedule | Granica | mm/dd/yyyy | Not Started |
Phase 2: Execute
| Deliverable | Owner | Date | Status |
|---|---|---|---|
| Copy datasets to “Golden” cloud storage Bucket | Granica | mm/dd/yyyy | Not Started |
| Crunch datasets in Granica Cloud (SaaS) or Hosted Sub-Account (Hosted) | Granica | mm/dd/yyyy | Not Started |
| Data validation and schema compatibility test results | Granica | mm/dd/yyyy | Not Started |
| End-to-end pipeline performance testing | Granica | mm/dd/yyyy | Not Started |
| Weekly status reports with progress and issues, if any | Granica | Ongoing | Not Started |
Phase 3: Executive Review
| Deliverable | Owner | Date | Status |
|---|---|---|---|
| Executive summary with pilot results and recommendations | Granica | mm/dd/yyyy | Not Started |
| Storage, performance, and ROI analysis | Both | mm/dd/yyyy | Not Started |
| Production rollout plan and timeline | Granica | mm/dd/yyyy | Not Started |
| Stakeholder presentations and supporting materials | Granica | mm/dd/yyyy | Not Started |
Phase 4: Next Steps
| Deliverable | Owner | Date | Status |
|---|---|---|---|
| Pilot closeout report with final results and lessons learned | Granica | mm/dd/yyyy | Not Started |
| Compressed datasets promoted to production | [Customer Name] | mm/dd/yyyy | Not Started |
| Knowledge transfer and handoff completed | Granica | mm/dd/yyyy | Not Started |
| AWS pilot environment decommissioned, if required | Both | mm/dd/yyyy | Not Started |
The pilot timeline has been carefully designed to balance the need for thorough testing and validation with the desire to rapidly demonstrate business value and ROI. The phased approach allows for early feedback and course correction, while the gated milestones ensure that key deliverables are met before proceeding to the next phase.
Pilot Results and Analysis
The Granica Crunch pilot at [Customer Name] delivered exceptional results across all key evaluation criteria, including storage reduction, query performance, data fidelity, and business value. This section provides a detailed analysis of the pilot results, along with supporting data and visualizations.
Storage Reduction
The primary objective of the pilot was to validate the storage reduction capabilities of Granica Crunch on [Customer Name]'s diverse dataset. The results exceeded expectations, with an average compression ratio of XX% across the NN pilot datasets. The following chart visualizes the storage reduction achieved for each dataset:
| Dataset | Original Size (TB) | Compressed Size (TB) | Compression Ratio |
|---|---|---|---|
| tbd | xx.xx | xx.xx | YY% |
| Total |
Data Validation
A key requirement for any compression solution is maintaining data integrity and fidelity through the compression/decompression process. To thoroughly validate data integrity, the pilot included a comprehensive data validation workstream with the following key activities:
- Row counts: Verified that the number of rows remained constant pre- and post-compression
- Statistical sampling: Randomly sampled 1000 rows from each dataset and verified byte-level equality
- Checksum validation: Computed checksums for each dataset pre- and post-compression and verified equality
- Schema validation: Verified that data types, precision, scale, and nullability remained unchanged
- Boundary case testing: Validated that MIN, MAX, DISTINCT, and NULL values were preserved
The following table summarizes the data validation results:
| Validation | Result |
|---|---|
| Row counts | XXX% match |
| Statistical sampling (1000 rows) | XXX% match |
| Checksum validation | XXX% match |
| Schema validation | XXX% match |
| Boundary case testing | XXX% match |
The data validation workstream conclusively proved that Granica Crunch achieved XXX% data fidelity across all pilot datasets, a critical milestone for building confidence and trust in the solution.
Query Performance
As part of the pilot, internal tests were conducted to validate the end-to-end performance of the data pipeline when processing compressed datasets.
The primary objective was to ensure that pipeline performance was at least equal to or better than the baseline performance on the original uncompressed data. Maintaining parity in performance is critical to ensure that compression does not introduce additional processing latency or overhead.
Query Latency Comparison
| Query Pattern | Avg Latency - Raw (s) | Avg Latency - Compressed (s) | Improvement |
|---|---|---|---|
| Large table scan | sss.s | sss.s | YY.Y% |
| Join | sss.s | sss.s | Y.Y% |
| Window function | sss.s | sss.s | YY.Y% |
Resource Utilization Comparison
| Query Pattern | Avg CPU - Raw (%) | Avg CPU - Compressed (%) | Avg Memory - Raw (GB) | Avg Memory - Compressed (GB) |
|---|---|---|---|---|
| Large table scan | YY.Y | YY.Y | XXX.X | XXX.X |
| Join | YY.Y | YY.Y | XXX.X | XXX.X |
| Window function | YY.Y | YY.Y | XXX.X | XXX.X |
The results indicated no observable performance penalty, confirming that the compression did not negatively impact the pipeline's efficiency.
Data Lakehouse Compatibility
Ensuring seamless compatibility with leading data lakehouse environments is critical for any compression solution. Granica Crunch has been thoroughly tested for compatibility with key data lakehouse platforms and query engines with the following compatibility results:
| Compatibility Matrix | Result |
|---|---|
| Spark (2.4.8+) | Fully supported |
| Hadoop (2.9+) | Fully supported |
| Hive (2.0+) | Fully supported |
| Presto (0.245) | Fully supported |
| Trino (356+) | Fully supported |
| Customer-specific test xx | Fully supported |
| Read/write operations | YYY% success |
| Query execution | YYY% success |
| Schema preservation | YYY% success |
This validation ensures that Granica Crunch integrates seamlessly with major data lakehouse platforms, maintaining data integrity and performance across all supported versions. Additionally, Granica is committed to flexibility—support for other platforms can be added based on evolving [Customer Name] needs, and we welcome specific requests to expand compatibility further.
Proposed Rollout and Next Steps
Based on the exceptional results of the Granica Crunch pilot at [Customer Name] across all key criteria - storage reduction, query performance, and data fidelity - we recommend immediately proceeding to a production rollout of the solution across the entire XX PB data lakehouse.
Beyond cost savings, Granica Crunch also delivers significant strategic benefits to [Customer Name] that are aligned with key organizational objectives:
- Improved performance and user experience for all data consumers
- Increased data retention to fuel AI/ML innovation
- More efficient use of cloud storage assets
- Simplified data management and operations
- Foundation for a scalable and sustainable data architecture
Appendix
ROI and Budgeting Guidance
The following table provides budgeting guidance for implementing Granica Crunch at [Customer Name] across three phases:
| Phase | Months | Data Types | Budget ($) | Savings ($) | ROI (%) |
|---|---|---|---|---|---|
| Start | M - M | Datatype A | $$$$K | $$$$K | YYY% |
| Scale | M - M | Datatype A + B | $$$$K | $$$$K | YYY% |
| Grow | M - M | Dataype A+B+C | $$$$K | $$$$K | YYY% |
| Total | Year 1 | Full Data Lakehouse + New Use Cases | $$$$K | $$$$K | YYY% |
[EXAMPLE]
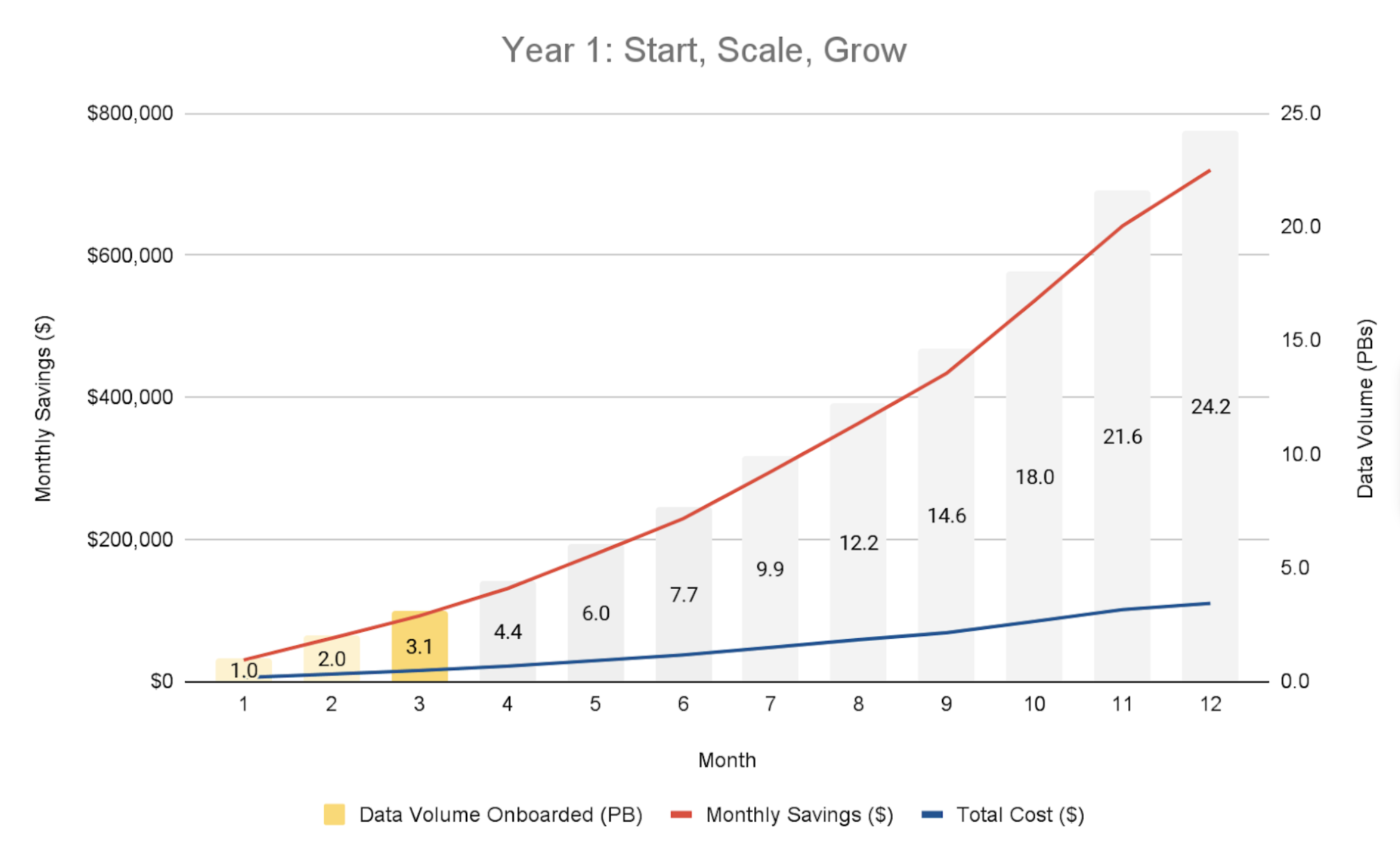
Key assumptions and notes:
- Compression ratios and cost savings for Dataset A files based on pilot results of YY% DRR
- Compression ratios and cost savings for Dataset B files based on YY% DRR
- Granica fees include licensing and support.
- AWS/GCP infrastructure costs not included (assumed to be cost-neutral)
- No additional headcount or resources required from [Customer Name]
- Production rollout to commence within 30 days following pilot acceptance
Technical Architecture and Infrastructure
[EXAMPLE IN AWS]
- Granica Crunch deployed in isolated AWS pilot account
- EC2 instances (r5d.4xlarge) used for compression compute
- Source datasets stored in S3 bucket (s3://[Customer Name]-pilot-raw)
- Target compressed datasets stored in separate S3 bucket (s3://[Customer Name]-pilot-compressed)
- EMR Serverless used for ad hoc query validation and testing
- All resources secured with KMS encryption and IAM least-privilege policies
Security and Compliance Considerations
[EXAMPLE IN AWS]
- Granica Crunch operates exclusively within [Customer Name]'s AWS account and VPC, with no external data transfer or processing
- All data is encrypted at rest with AES-256 using [Customer Name]'s KMS keys
- All data is encrypted in transit with TLS 1.2+
- IAM policies enforce least-privilege access control to S3 buckets and Glue Data Catalog
- Granica personnel do not have access to any [Customer Name] data
- Granica Crunch is certified for SOC 2 Type II. With ISO 27001 coming soon.
- Data is not persisted on any Granica EC2 instances; all data resides in [Customer Name]'s S3 buckets
- Secrets such as AWS credentials are stored in Hashicorp Vault with dynamic secret generation
- All API endpoints use mutual TLS (mTLS) authentication
- Vulnerability scanning and penetration testing conducted annually by an independent third party
- Incident response plan tested annually with tabletop exercises