Use Case: LLM Data Privacy
Learn how Screen enables LLM data privacy
The problem
Generative AI and LLMs have emerged as powerful tools and levers for innovation, but this has come with major new concerns around data privacy. Many of these use cases require or involve sensitive or private information, and there have already been numerous cases of data breaches, even from leading providers such as OpenAI. In addition, data retained for training or model improvement can easily be memorized and leaked by these generative models.
As a result of these challenges, many organizations have outright banned or severely limited their use of these technologies. This leaves organizations stuck between a rock and a hard place - missing out on a huge wave of innovation, or putting sensitive data at risk.
Another solution organizations have looked to in the face of these challenges is internally trained or fine-tuned models, which are not hosted externally. However, this leads to many of the same data privacy challenges, and often at much larger scale, due to the massive volume of data used to train these models.
Regardless of the approach taken, data privacy remains a central challenge and risk.
How we help
Granica Screen offers a comprehensive approach to protect sensitive data across LLM use cases, both internal and external.
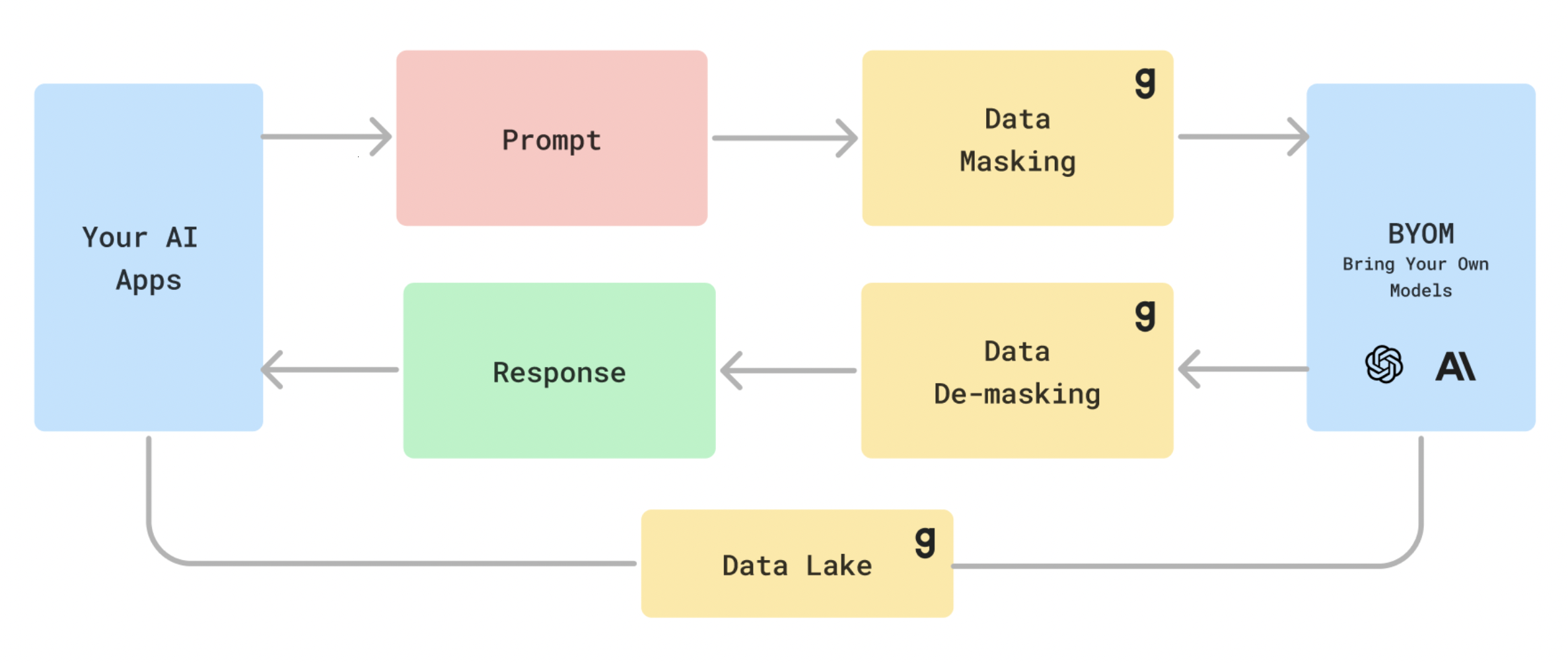
Granica Screen can detect and mask any sensitive data being sent to LLMs, so that the intent of the prompt can still be carried out, but with placeholders for sensitive information. These placeholders can then be unmasked when processing the LLM response, so that the end user still gets the full intended behavior from their prompt.
In addition, Granica Screen also operates efficiently at scale during the model training process, to mask or otherwise obfuscate sensitive data before it is used for training.
What you need
Best-in-class accuracy
Accuracy is a fundamental requirement for effective data masking, including both high precision and recall. Low precision approaches will overmask the data and render the prompt useless, while low recall models leak a significant amount of sensitive data to LLMs. A combination of high precision and high recall ensures correct LLM behavior with protection of sensitive data.
Accuracy is both difficult to achieve and to measure, since every dataset is unique and benefits from a different approach. Granica Screen is powered by an adaptive classification system that learns from a dataset and maximizes the accuracy of results.
Granica Screen provides demonstrably superior classification accuracy across datasets and use cases. We benchmark our performance on a variety of synthetic data, such as data generated by the Presidio Research library, as well as real datasets across a range of filetypes and industries.
Comprehensive Coverage
LLMs often take end user input directly, which can come in a wide and often unpredictable variety of formats, languages, and types of sensitive data. Any data privacy solution must be robust to the wide range of possible data being sent to an LLM, or risk having significant blind spots and wide variability in accuracy when handling unexpected data.
Granica Screen supports a wide range of languages and locales, as well as a large number of types of sensitive data and PII. We are constantly expanding and updating this list so that any sensitive data being sent to an LLM can be correctly masked.
Highly performant, Low latency API
In order to integrate data masking into LLM workflows, the process must do so with minimal disruption to the end user. That means consistently low latency, even for large prompts which are commonly generated by RAG use cases. This is no trivial task - accurate sensitive data detection and masking is a computationally expensive task, due to the numerous components needed to support the wide variety of input prompts and types of sensitive data which might be present.
Granica Screen is built on top of Granica's data processing platform, which serves customers storing petabytes of data and billions of objects, while operating in a high throughput, low latency environment. We optimize our workflows to minimize performance disruptions from adding additional steps to LLM workflows.
Cost-efficient processing
Due to the computational complexity of sensitive data detection, naive solutions can be extremely expensive to run, exacerbating the already high costs of working with LLMs. This is especially important when working with training data, where the massive scale of data required makes many approaches completely cost-prohibitive to implement. Some solutions cost as much as the LLM itself to run!
Granica Screen is optimized for cost efficiency from top to bottom, through our algorithmic approaches, instruction optimization, and cluster and instance management.
Customizable to your workflows
LLM product development is a fast-moving space, and organizations are quickly adapting their approaches in terms of prompting, fine-tuning, RAG, and more. Any solution needs to be able to rapidly adapt to differences in input formats and content in order to effectively identify sensitive data. In addition, flexible configuration of masking approaches is key to preserving the behavior of LLMs without directly passing sensitive data in the prompt.
Granica Screen has customizable behavior in terms of both detection and masking through a wide range of configuration options within our API. The team continually expands these options while identifying the best approaches for LLM integration.
Integration Scenarios
External LLM
Instead of sending user prompts directly to an external LLM, they can first be masked using the Granica Screen API. This is automatically configured to include common sensitive data types across a wide range of locales and languages, and covered by common data privacy regulations such as GDPR, CCPA, HIPAA, and more.
This configuration can also be further customized based on the needs of your organization, such as defining additional business-specific sensitive entities, making exceptions for data known to be non-sensitive, or selecting an optimized masking method based on the LLM being used.
Of course, in this case the LLM response will also be masked - but this can be unmasked using the mapping provided by Granica Screen to reverse the masking process for the end user.
Training Data
Training data for LLMs often amounts to trillions of tokens, generally stored in a data lake due to the massive volume. Granica Screen directly integrates with cloud storage solutions such as AWS S3 and Google Cloud Storage in order to efficiently scan and protect this data in a batch setting.
In addition, the customizations used in other contexts, such as during LLM inference, can easily be ported over so that business-specific configurations can easily be shared across all of your data.
Getting started is extremely simple - simply grant the Granica cluster access to the relevant data and configure the Granica policy (or use the default settings), and Granica Screen will automatically scan and mask the data.