Granica Crunch
Lakehouse-Native Compression Optimization for Analytics, ML and AI
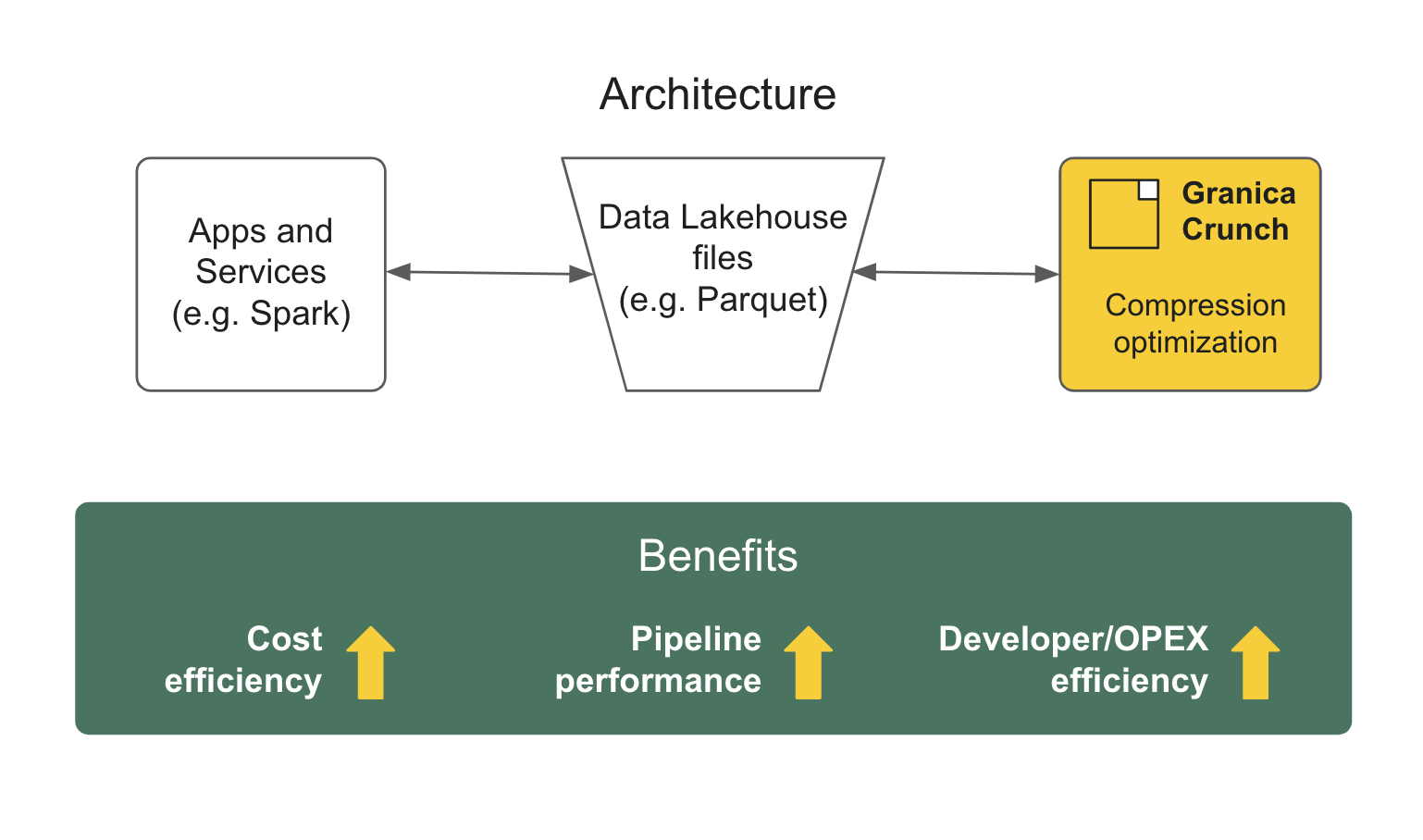
Granica Crunch is the industry's first cloud cost optimization solution purpose-built for lakehouse data. It applies lakehouse-native data compression optimization to high volume datasets heavily used in analytics, ML and AI. Such data is stored in columnar formats, especially Apache Parquet, which typically already use a form of compression such as Snappy, zlid, zstd and others.
Crunch optimizes the compression used inside these formats, dramatically shrinking the physical size of the columnar files. This in turn dramatically shrinks the cost to store and transfer them while also speeding queries run against them. The Crunch compression optimizer uses advanced machine learning-powered algorithms which run transparently in the background learning from and adapting to your data to build compression recipes which it uses to ensure that both existing and incoming data is optimally compressed.
The problem
Organizations of all sizes realize they need to focus on being a lot more efficient with their resources in order to keep investing into their strategic priorities. For most (if not all) organizations today, AI is already a strategic priority and it is becoming more strategic every day.
In order to minimize the impact on your people, culture and sustainability, an urgent priority is thus to apply FinOps principles to identify and eliminate any significant spending inefficiencies. Most organizations have made at least some progress with compute inefficiencies for example by shutting down stranded instances.
As it turns out, modern data lakes, lakehouses and AI systems with their large volumes of data in the public cloud represent a significant source of data inefficiency. The potential savings from applying Crunch to optimize that data and eliminate those inefficiencies is dramatic.
How Granica Crunch helps
Analogous to how a query optimizer further speeds the performance of existing SQL queries, Crunch is a compression optimizer which further reduces the size (and increases the efficiency) of existing columnar files such as Apache Parquet while remaining standards-compliant.
Granica Crunch reduces the cost to store and transfer petabyte-scale lakehouse data typically by 15-60%, depending on the structure and pre-existing compression of your columnar files. If you’re storing 10 petabytes of Parquet in Amazon S3 or Google Cloud Storage-backed lakehouses that translates into ~$1.2M per year of gross cash savings (not inclusive of Granica licensing) from reducing at-rest storage costs. The smaller files produced by Crunch also reduce cost and time for data transfers (e.g. loading training data sets) and they also increase query performance and reduce associated compute costs. Better, more efficient data delivers big benefits across the data environment.
Crunch is the simplest and most secure way to significantly reduce the cost associated with large scale lakehouse data without manually opimizing columnar compression, or having to resort to archival and/or deletion. With Crunch you can cost-effectively keep, grow, and most importantly use your data sets to maximize analytical value and model performance and ultimately your ROI.
- Reduce cost to store and transfer data by up to 60%
- Reduce data transfer times by up to 60%
- Increase query performance and data loading times by up to 56%
- Reduce compute cost and time for queries, downstream transformation and training stages
- Increase model performance by performing more training at the same cost
Use cases
Lower costs to store & move data
Crunch compression optimization shrinks the physical size of your columnar-optimized files, lowering at-rest storage and data transfer costs by up to 60% for large-scale lakehouse data sets used for analytics, ML and AI.
Faster cross-region replication
Smaller files also make data transfers and replication up to 60% faster, addressing AI-related compute scarcity, compliance, disaster recovery and other use cases demanding bulk data transfers.
Faster processing
Smaller files are also faster files - they accelerate any process bottlenecked by network or IO bandwidth, from queries to data loading for model training. Up to 56% faster based on TPC-DS benchmarks.
Key characteristics and features
- Multi-Cloud—Supports public cloud object stores: Amazon S3 and GCP Google Cloud Storage
- Lakehouse-Native IO—Ensures data remains in standard, open columnar formats and supports Apache Parquet with other formats coming soon. Crunch is not in the read path and requires no changes to applications working with Crunch-optimized files, enabling significant savings potential with fast time to value. Supports Apache Spark and Trino, with Databricks support coming soon.
- Structure-Adaptive Compression Optimizer-Advanced ML-based algorithms dynamically control, adapt and tune lossless compression and encoding algorithms such as zstd to each file’s unique structure to make them as compact and efficient as possible, lowering at-rest lakehouse storage costs and cross-region transfer costs by up to 60% based on TPC-DS benchmarks. Enables data teams to dramatically reduce cost, improve ROI and to address AI-related compute scarcity, compliance, and disaster recovery.
- Data-Driven Query Boost-Optimized files enhance query execution and efficiency, accelerating query performance of any application, model training, or ELT/ETL process bottlenecked by network or I/O by up to 50% based on TPC-DS benchmarks. Faster queries improve decision making and speed model development.
- Zero-Copy Architecture-Compresses and updates files in place, without the need to create copies, further lowering costs and reducing data management overhead.
- Exabyte-Scale-Background data processing is able to handle an arbitrary volume of data to maximize savings across the lakehouse data footprint.
- Secure—Data never leaves your environment: Crunch runs entirely within your VPC and respects your security policies
- Resilient—Highly available clusters ensure always-on data access
- Powerfully simple—Start crunching your data in-place and cutting costs in 30 minutes, with 1 command
Crunch inherits many of these characteristics via internal shared services, see the Granica architecture for more details.