Architecture
Understand the Granica architecture.
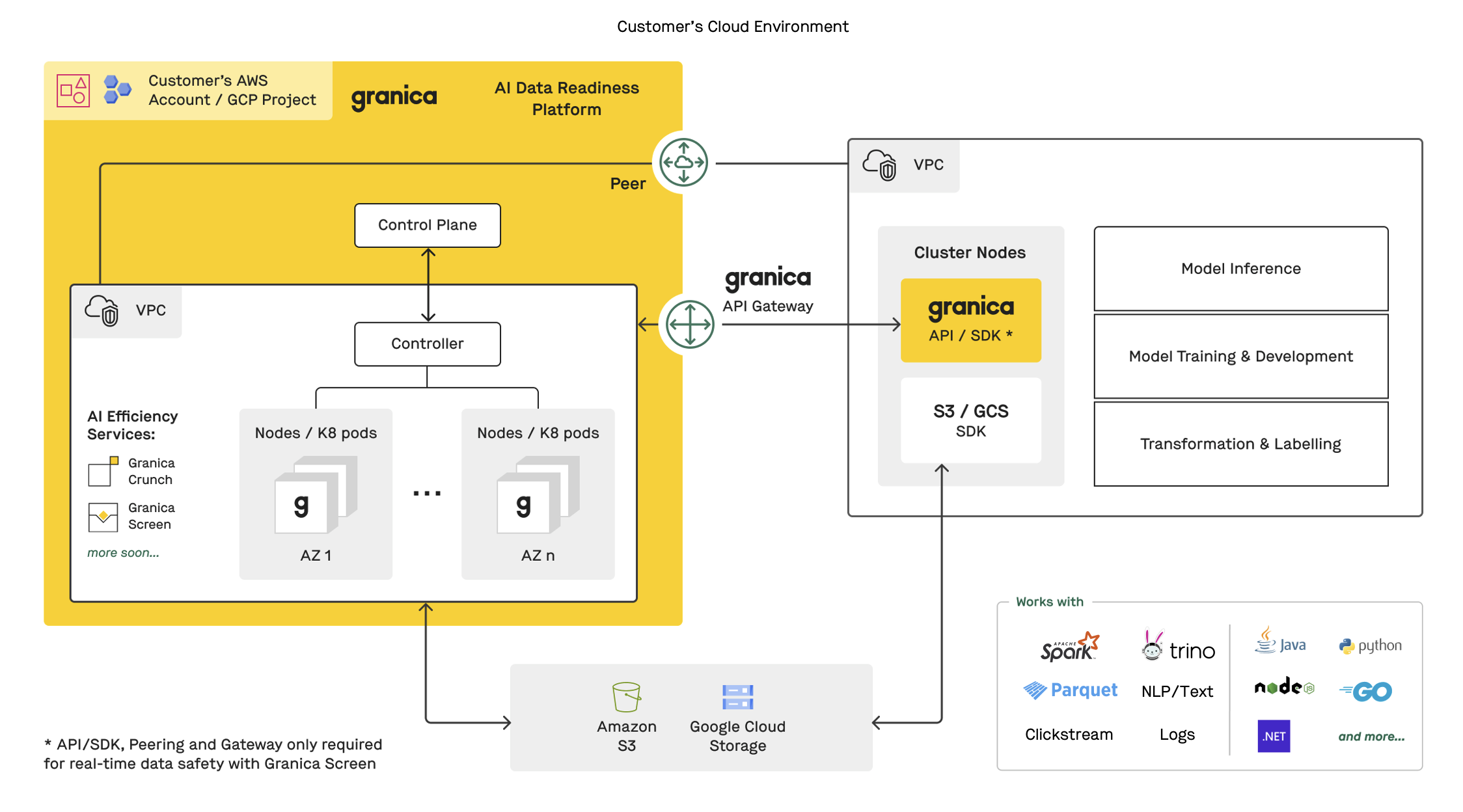
Granica helps companies build and manage high quality data for AI, at scale. The Granica AI data platform utilizes a cloud-prem architecture with a control and data plane that runs entirely in your cloud environment to process data in your cloud data lakehouses and their underlying object stores, to make your data AI-ready. Our platform uses AI to continuously improve your data, making your projects faster and more effective over time.
Granica typically processes your data in the background, reading from and writing to cloud storage without requiring any application integration. Some services, such as real-time data safety, use the Granica Screen API/SDK to integrate with your applications (for example LLM-enabled applications). In either case your data remains secure and safe because it never leaves your environment.
How Granica helps
Our platform enables us to solve for some of the biggest AI challenges:
Increase data safety for AI and LLMs. Accurately protect the sensitive information with the largest attack surface and AI training risk - high volume unstructured, NLP and tabular data sets. Learn more about Granica Screen.
Shrink cloud costs for lakehouse data. Reduce monthly at-rest and cross-region transfer costs for high volume data sets in columnar formats like Apache Parquet by up to 60%. Learn more about Granica Crunch.
Speed time-to-insight for lakehouse data. Increase query performance and data processing times for columnar formats by up to 56%, while also improving AI/ML and data engineering productivity. Learn more about Granica Crunch.
Key architectural characteristics
- Your data never leaves your environment. Essential capabilities such as encryption for data (in transit and at rest) and fine-grained Access Controls are built-in providing enterprise-grade data security.
- Our control and data planes self-deploy into a dedicated account/project and VPC in your environment and run as a single tenant, respecting all of your security policies. Our architecture is optimized to efficiently utilize multiple availability zones (AZs) for availability and reliability. Our platform leverages VPC peering to connect our API-based services with your applications, minimizing cross-AZ charges.
- Granica delivers the data security, compliance and control benefits of a traditional VPC combined with the vendor-managed benefits of SaaS. This is why enterprises, especially those in regulated industries with highly sensitive data such as financial services, healthcare, and government agencies, choose Granica.
Shared infrastructure
All Granica products are built on shared Granica infrastructure, the majority of which exists to ensure things “just work”. Robust infrastructure exists for data integrity, availability, elastic scaling, encryption, 100% non-disruptive upgrades, telemetry and more. Granica also provides customer-facing capabilities for reporting, billing and analytics. Let’s explore some of this internal shared infrastructure in more detail.
Data integrity (Granica Crunch)
Granica implements multiple levels of data integrity to ensure your data is always protected.
Object integrity
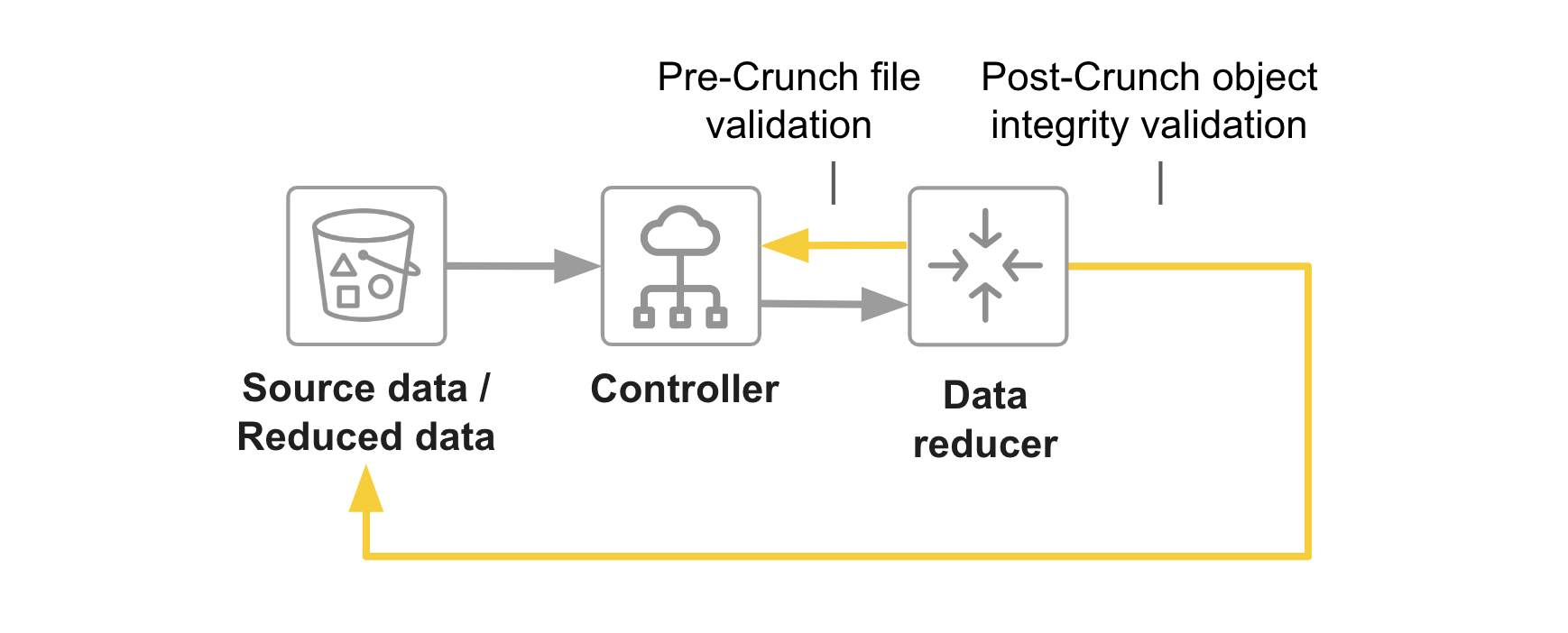
- Pre-Crunch file validation. Before crunching, reads the source file to ensure it is consistent with the native format. For example, for Parquet, ensure the file is a valid parquet file.
- Post-Crunch object integrity validation. Immediately after Crunch reduces a source object, Granica performs logical data validation by comparing checksums on source and reduced data.
Integrity failure handling
In the unlikely event of any integrity failure Crunch stops crunching new objects and our team is alerted. When the integrity failure is resolved, Crunch resumes crunching.
High availability (HA)
Granica provides >99.99% high availability (HA) to Granica products, building upon cloud-native primitives such as AWS EKS Availability Groups. We deliver this availability extremely cost-efficiently by automatically leveraging spot instances where possible.

All efficiency services are implemented using kubernetes pods running across a cluster of compute instances or nodes. These pods are made highly available using a minimum 2-node cluster consisting of 24x7 on-demand instances. As you enable more applications to use our services, Granica elastically spins up additional spot instances and service pods to handle the increased load on the system. We distribute these pods across the cluster instances, using a Broker pod to manage requests to these distributed service pods.
In addition to providing HA for service pods running on the 2-node on-demand cluster, Granica provides HA for service pods distributed across any spot instances. In this way we deliver >99.99% availability for all pods across all instances, even if no spot instances are available.
Elastic scaling
Granica takes full advantage of the inherent elasticity of public cloud infrastructure to ensure consistent performance regardless of your data scale.
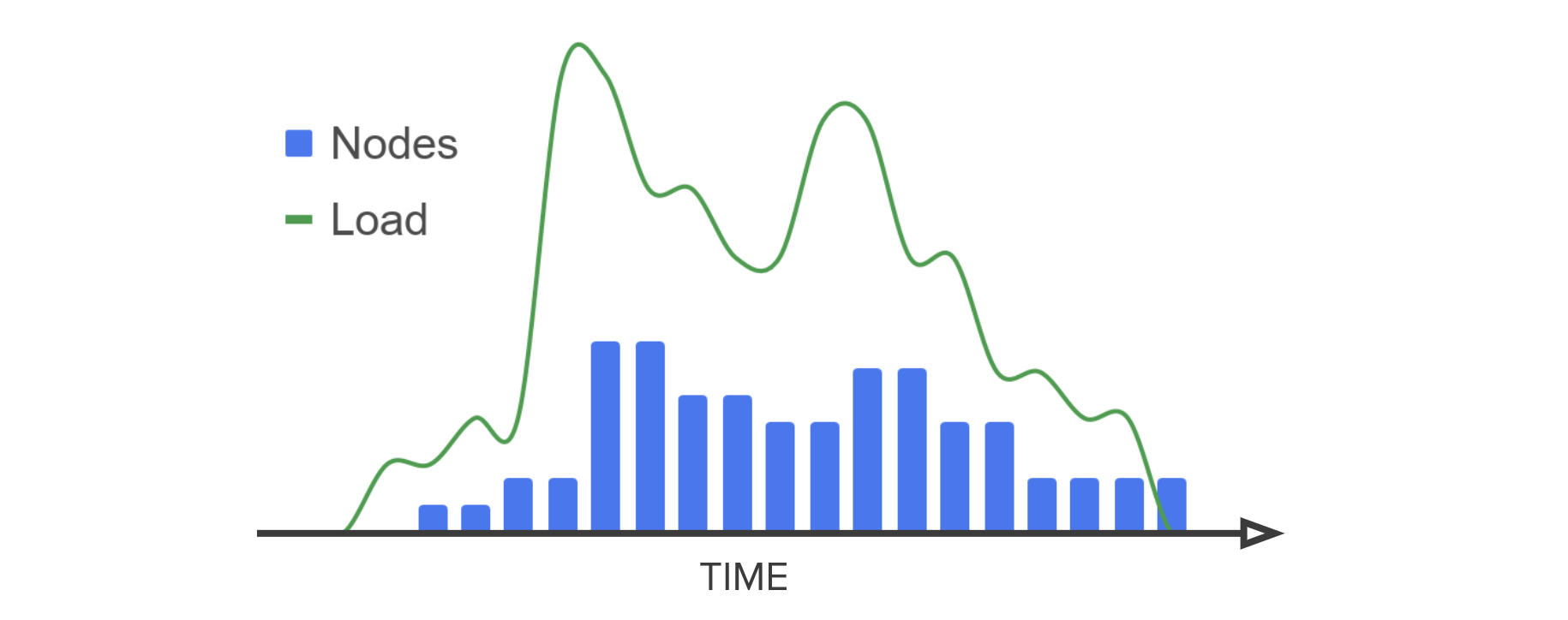 Granica Crunch is a background service and is not in the read path. It compresses any size columnar data volume via high processing throughput of 150MBps per node. All compute resources are also completely elastic, utilizing autoscaling k8s clusters to automatically and dynamically scale from zero to n nodes and potentially back to zero depending on volume of data to be crunched (the load). In this way Granica delivers effectively infinite scalability for your environment.
Granica Crunch is a background service and is not in the read path. It compresses any size columnar data volume via high processing throughput of 150MBps per node. All compute resources are also completely elastic, utilizing autoscaling k8s clusters to automatically and dynamically scale from zero to n nodes and potentially back to zero depending on volume of data to be crunched (the load). In this way Granica delivers effectively infinite scalability for your environment.
Whenever possible, Granica utilizes the largest available spot instances for these elastic nodes in order to complete compute work as fast as possible (and then shut down), thus maximizing performance with minimum cloud infrastructure costs.
Encryption
The Granica data path runs entirely within your VPC and respects your security policies.
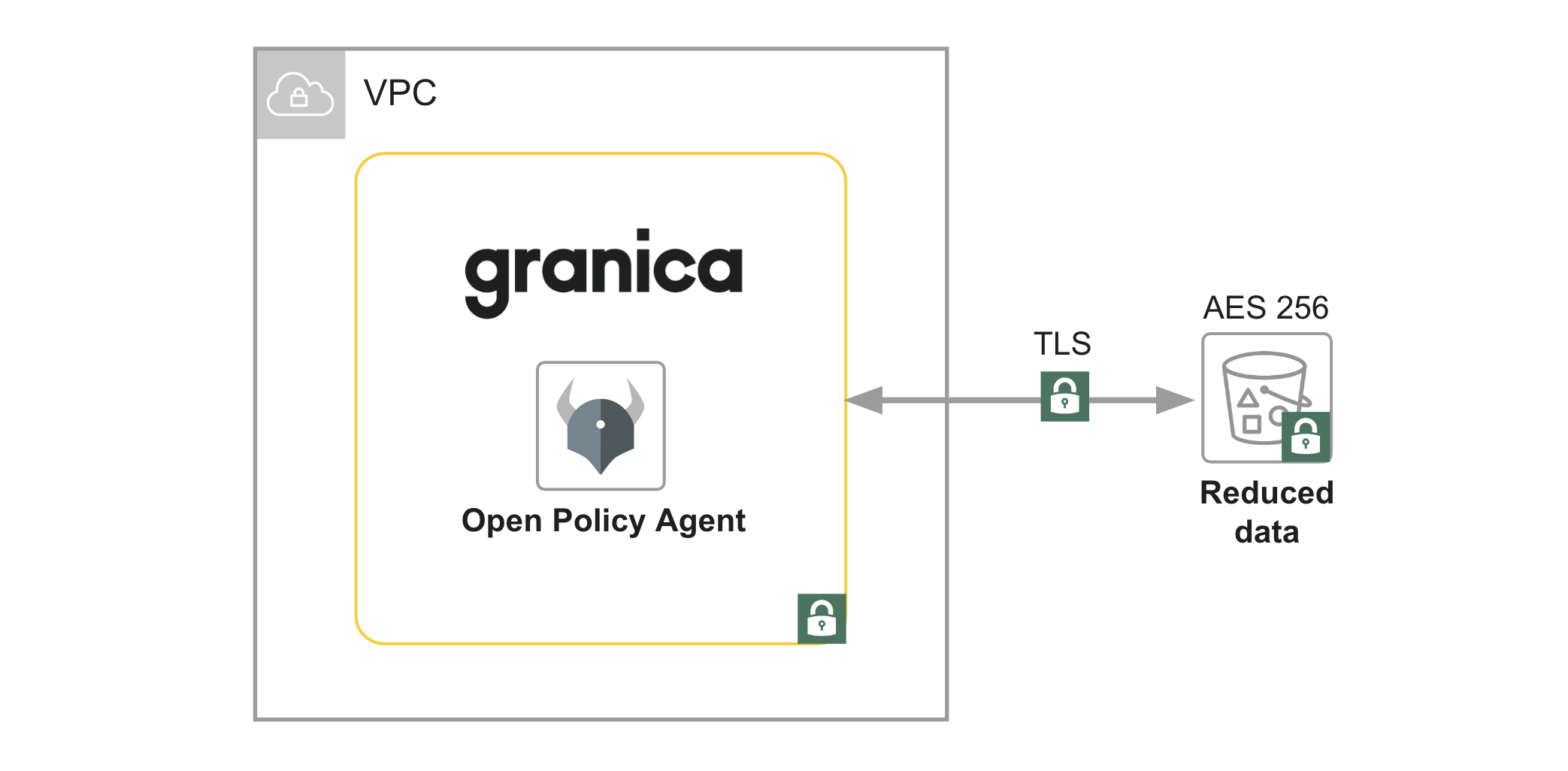
Your data never leaves your cloud environment, and Granica (and Crunch by extension) relies upon the native encryption services provided by the public cloud provider of choice (e.g. S3 server side encryption) to encrypt both data at rest and data in motion. As a result, all data at rest is AES 256 encrypted, and all data at motion is TLS encrypted.
Granica also makes Amazon S3 more secure than it is natively, particularly when it comes to buckets with public access. Unlike the ACL by ACL approach AWS provides, Granica offers global policies for data access with a centralized Open Policy Agent and Gatekeeper services account. Your apps can continue to define their own ACLs, and then handshake with Granica for global allow/deny for example to globally block public access.
Non-disruptive upgrades
Granica upgrades are transparent to your applications. This enables you to easily take advantage of new features and capabilities and maximize the value you get from our platform.
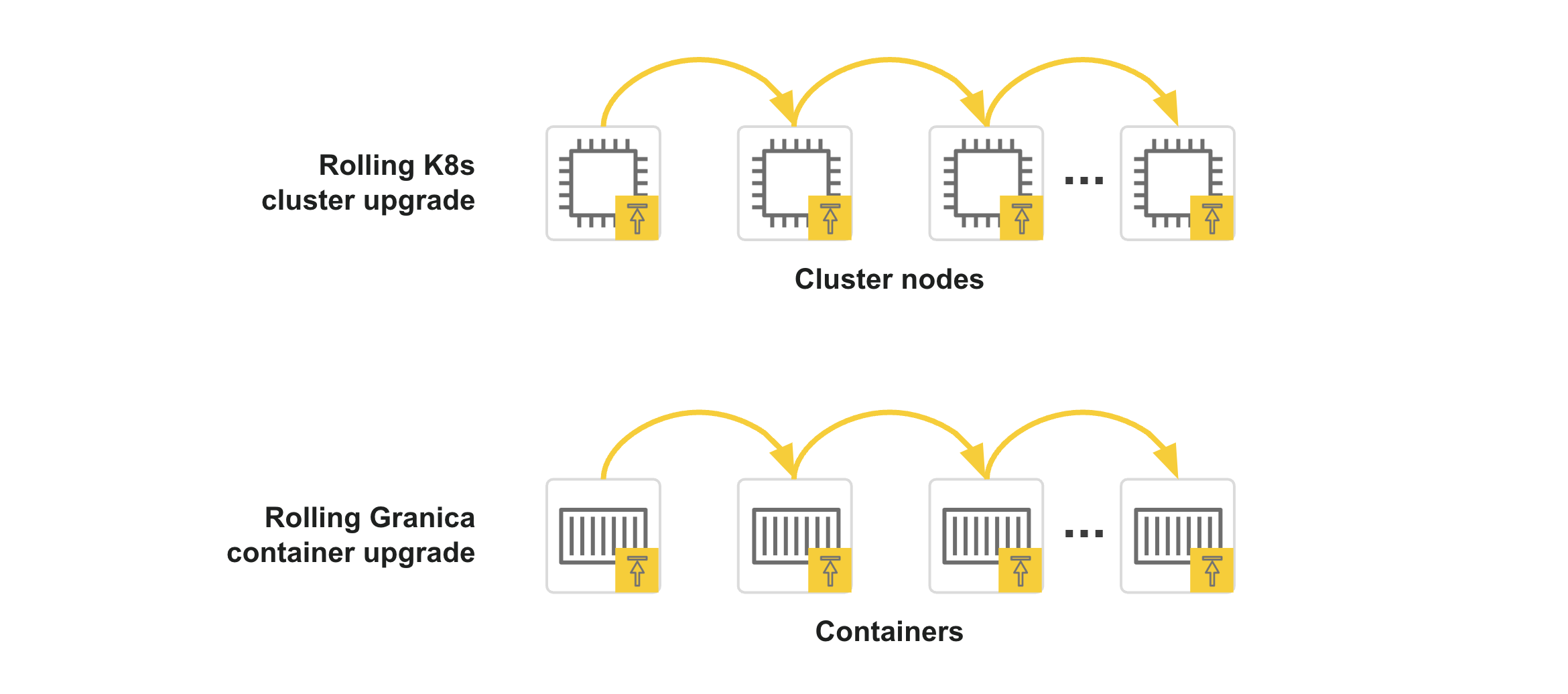
Granica implements a rolling upgrade (and rollback) approach across all service pods and containers, as well as underlying Kubernetes cluster infrastructure. This approach ensures that upgrades do not affect availability or performance. By default, your Granica deployment stays up to date with new versions automatically. You can manually initiate an upgrade at any time via the granica update command. And you can optionally configure upgrades to only happen when initiated manually.