Use Case: Increase AI dev/test agility (Coming Soon)
Learn how Crunch enables free and blazingly fast copies.
The problem
There are many reasons you may want to make copies of your objects and buckets, whether for AI testing, development, backup, disaster recovery, reporting and analytics etc. It is not unusual for their to be 10 or more secondary copies of each source data set floating around. The entire discipline of Copy Data Management (CDM) emerged over a decade ago to help contain costs with various lifecycle policies given the copies are so expensive.
Unfortunately these costs often become a real constraint, with mandates limiting either the number of copies you can make or the total $ cost associated with the copies. These constraints complicate the AI R&D process, slowing down development velocity and exacerbating time-to-market and quality trade-offs.
The copy operations themselves can also take a significant amount of time especially for large data sets, for example petabyte-scale copy operations can take weeks to complete. And while there are workarounds to speed things up somewhat (e.g. manually splitting and parallelizing, using S3 batch operations, EMR S3DistCp etc.) these are complicated and unwieldly.
How we help
Granica Crunch solves all of these problems at once:
- You can create copies instantaneously, regardless of the scale of the data
- Your copies are essentially free
- You can simply use the
cpcommand
How it works
Crunch accomplishes this by using internal metadata operations instead of full raw data operations. When you copy a crunched bucket Crunch simply duplicates its internal metadata for that bucket (and not the full data set) thus creating “virtual” copies of your data. The metadata which Crunch manages and stores for any given bucket, even at PB scale, is very small and thus copy operations complete in 10s of milliseconds (effectively instantly) and the virtual copies themselves incur minimal storage capacity and cost.
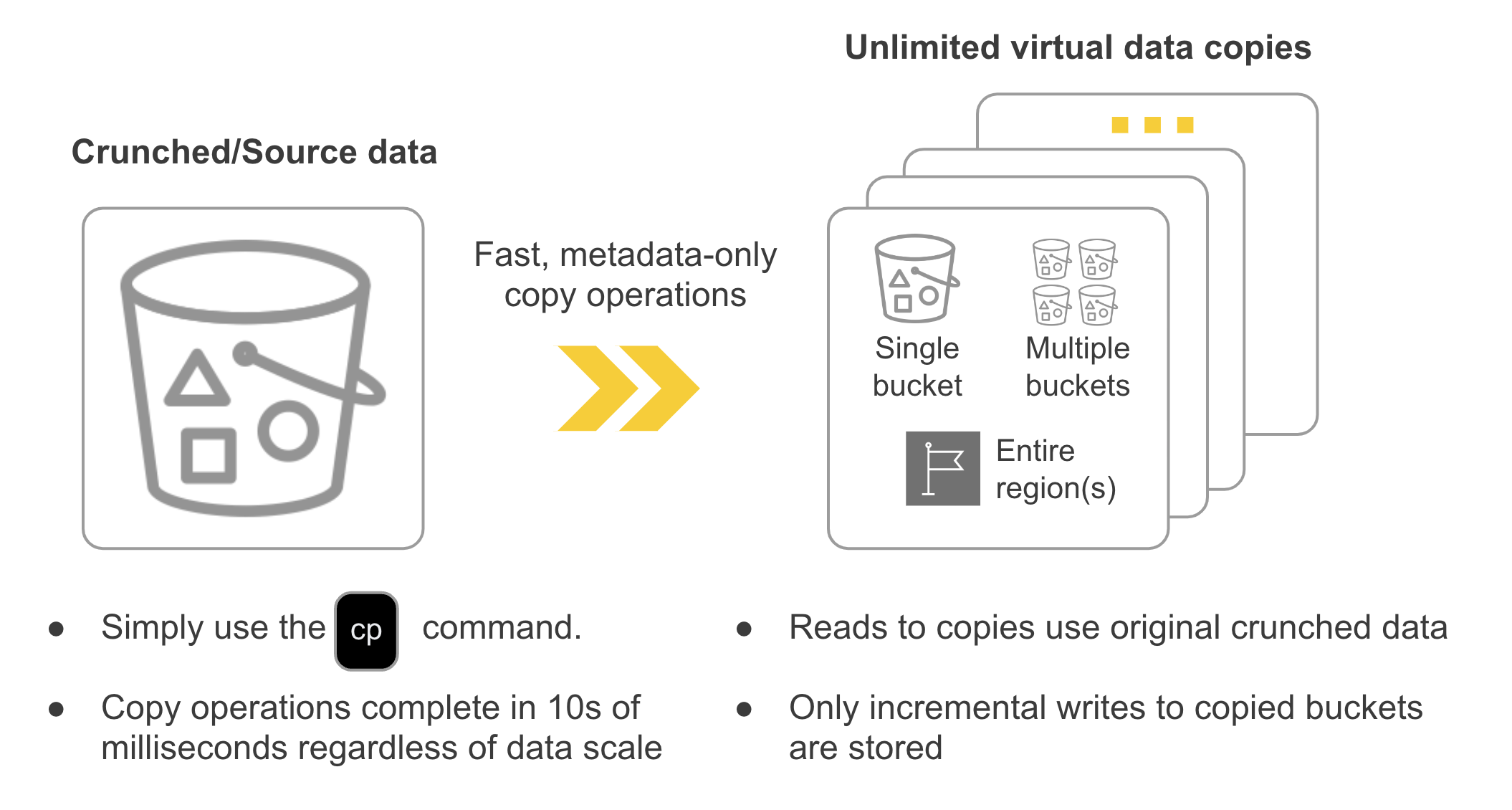
You can use the Granica CLI plug-in to create, share and access these virtual copies of your buckets using the same AWS and GCS CLI commands you are familiar with, and they appear as full data copies to Crunch-enabled applications. Crunch adds ~zero read/write latency to these virtual copies, ensuring fast transparent access.
As a result you can instantly create as many copies as you need or want, whether of a single bucket, multiple buckets, or even entire regions - all without materially increasing your cloud storage bill. In effect, Crunch eliminates the need for CDM to control costs, dramatically simplifying your AI pipeline and dev/test workflows.
Usage
note
The following commands make use of the Granica AWS CLI plugin interact with Crunch through aws s3 commands.
The S3 cp command is used to copy files from one bucket to another bucket. Note: Update the command to include your source and destination bucket names.
Copy a file from one bucket to another
Give the file a new name in the target bucket
Recursively copy S3 objects (all contents of bucket) to another bucket
Verify the objects that are copied
You can verify the contents of the source and target buckets by running the following commands:
You can compare objects that are in the source and target buckets by using the outputs that are saved to files in the {cloud} CLI directory. See the following example output: