Granica Crunch for LiDAR point cloud data
Learn how to increase efficiency for both storage and compute.
LiDAR (light detection and ranging) is an optical technique that uses laser light to measure surfaces with high accuracy, for example of the earth or of objects on city streets, in order to create 3D maps. Its versatility and high resolution give it applications in many areas, such as mapping and location services, meteorology, archaeology, rainforest monitoring, urban planning and more. LiDAR has long been deployed in satellites and in aircraft, and it is now a key component of many autonomous vehicles (AVs)
LiDAR sensors generate mass point cloud datasets which are typically uploaded to the public cloud, for example to Amazon S3 or Google cloud storage. The rapidly expanding use of LiDAR means that the cost to store that data has becoming very significant. We have customers ingesting multiple terabytes (TBs) of LiDAR data each day, adding hundreds of thousands of dollars per year in cost - each and every year. Of course the value in LiDAR comes from processing and analyzing it, for example to train AI models, and the compute costs as well as the time to do so are also scaling with the data volume. These efficiency challenges ultimately constrain what AI and data teams can achieve.
Introducing LiDAR point cloud compression
Granica Crunch delivers ~65% data reduction for LiDAR point cloud data, and as a result dramatically cuts associated cloud storage costs as well as downstream compute costs and processing time. Crunch achieves this via a lossy compression algorithm that eliminates useless noise from the data.
LiDAR sensors used for self-driving vehicles typically advertise a distance accuracy of 1 cm. However, LiDAR coordinates are often stored with much higher precision than this, for example as 32-bit floats which are precise to 100nm, or as doubles which are precise to less than a femtometer. The stored data about these tiny length scales is meaningless – and there’s a lot of it. We can save space by getting rid of that meaningless information, with no harm to data quality.
Our algorithm estimates the sensor noise in LiDAR data individually for each point. Using that estimate, it rounds the point coordinates to a precision well below the noise level. The algorithm includes safeguards to ensure that, even if the sensor noise estimation fails, the change in the point coordinates will be almost undetectable.
Hear from our researchers Eric and Evan as they dive into the details and show a demo.

Before/after comparison
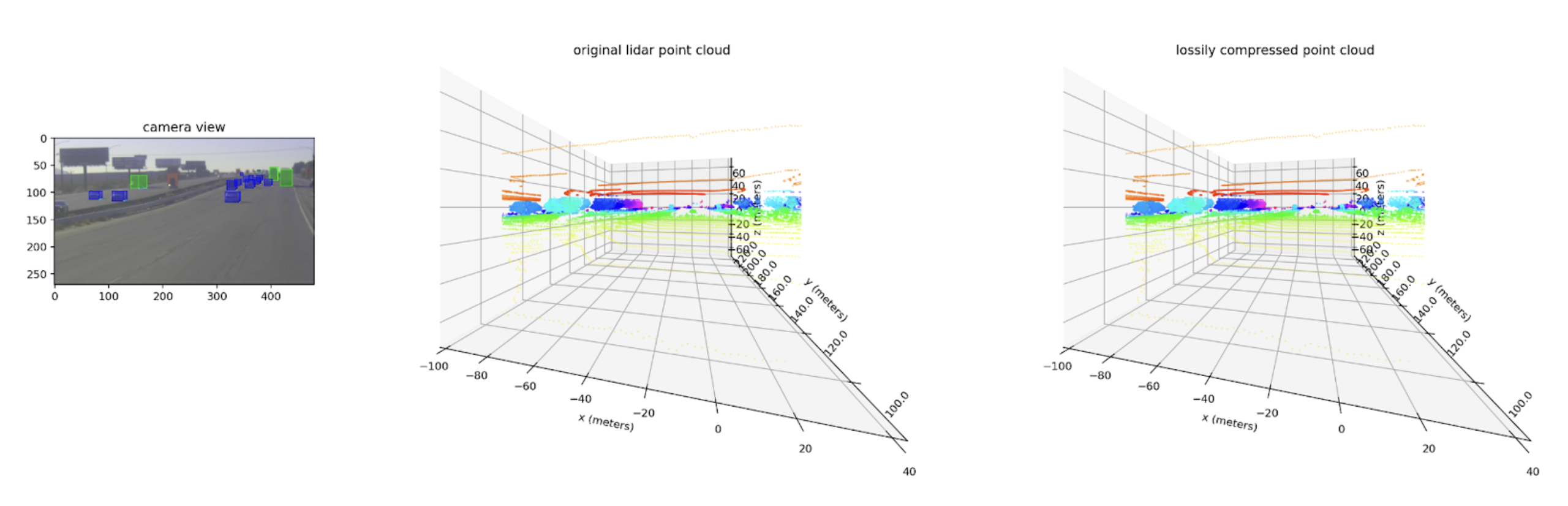
Below is an example camera scene and corresponding lidar point cloud, original and lossily compressed. At this distance, they appear identical.
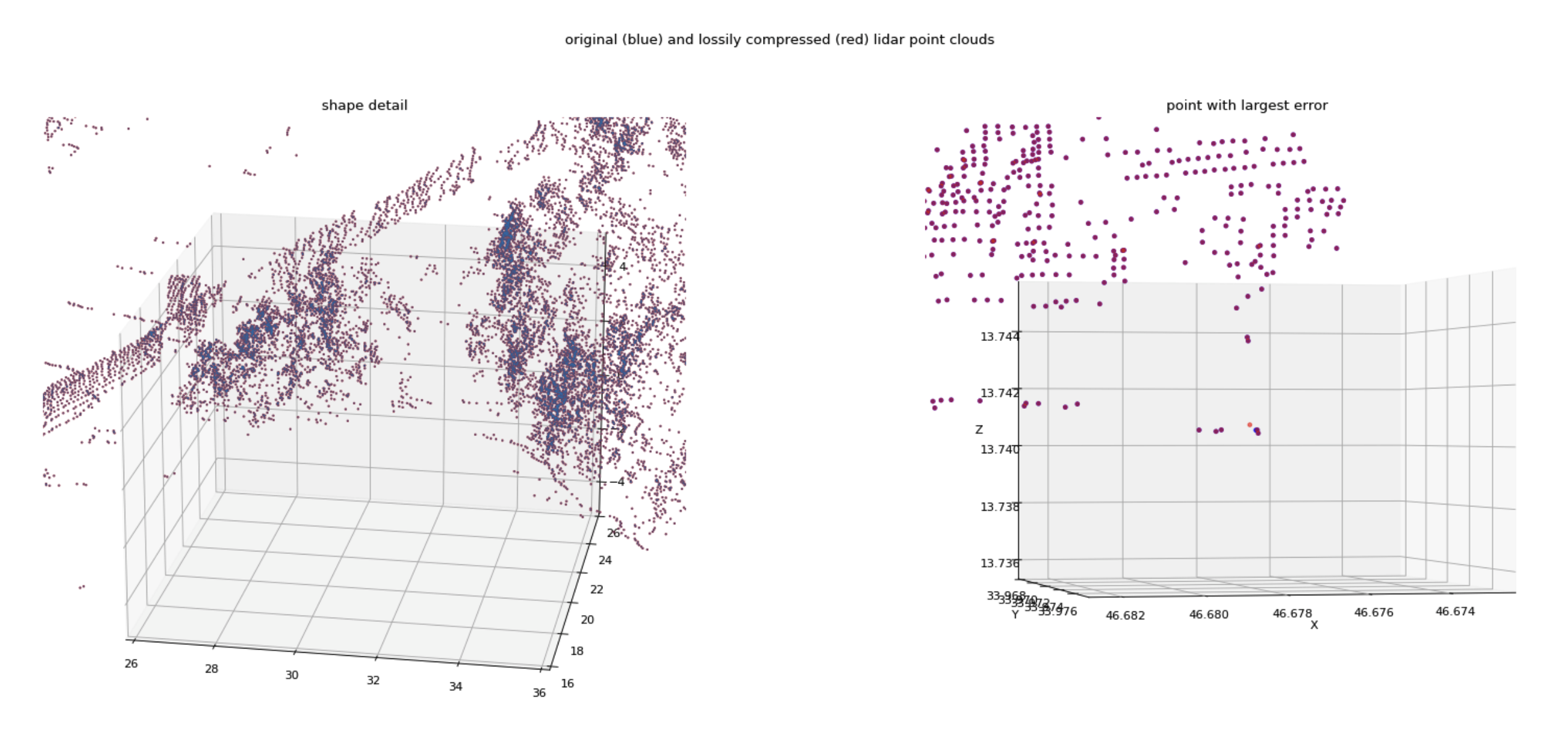
Next we see the detail of lidar point clouds with original points in blue and lossily compressed points in red. The left is a 10 meter cube; the right is a 1 cm cube. Most points have a nearly identical position. Even the point with the greatest error has an error much smaller than a centimeter, and smaller than the typical distance between measured points.
All-in results
The below results show the data reduction our lossy algorithm (green) achieves compared to our benchmark structure-aware lossless algorithm (orange) and the state of the art without our product (blue).
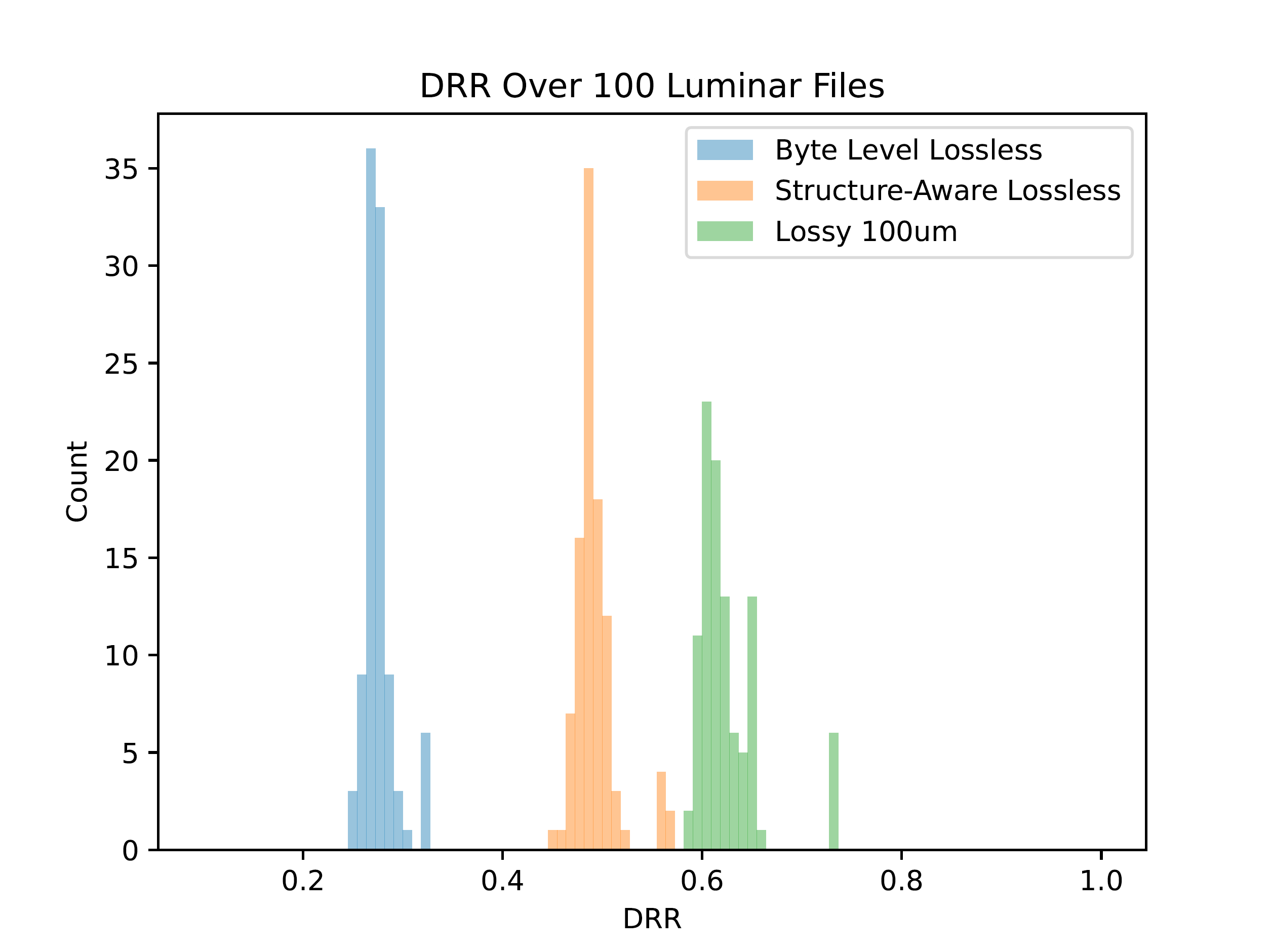
With our algorithm tuned so that no point moves more than a tenth of a millimeter, we achieve ~17 ppts (percentage points) more reduction compared to our lossless benchmark. Overall, our algorithm achieves ~65% data reduction on LiDAR point cloud data – with no change in data quality.